

社内共有ドキュメントからの抜粋で、一部匿名化処理を施しています。
プロジェクト概览
これは、cursorが描画をサポートしていないため、商品詳細フロントエンドアプリケーションの理解に基づいてcursorで描画されたSVG形式の画像です。
全体的には、プロジェクトの状況、プロジェクト構造、技術選定、およびいくつかのサブpackageの役割を大まかに説明しています。しかし、画像全体には、テキストのオーバーフロー、重なり、配置の問題など、詳細に多くの問題があります。AIに何度も修正を依頼しましたが、改善されませんでした。これは、合理的なエネルギー効率比でAIが生成できる最良の結果であり、まあまあといったところです。
cursorエディタ自体に関する実践
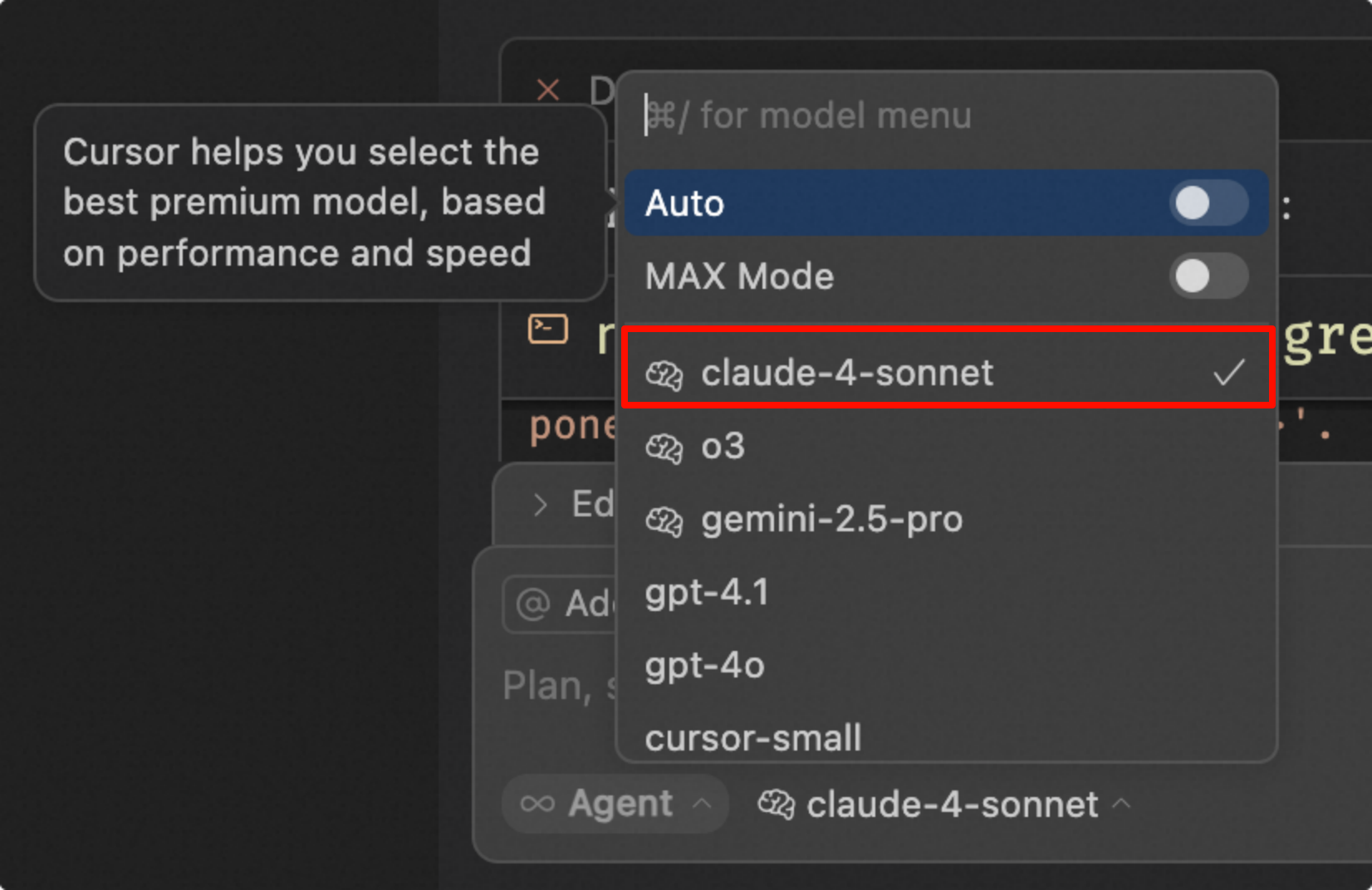
特定のモデルを指定する
autoモードは使用せず、オフにしてclaude-4を指定してください。現在のテストでは、その効果は良好です。デフォルトのautoモデルを使用すると、回答の品質が非常に不安定になります。
cursor rule の実践
10のフレーズで`cursor`のプログラミングレベルを10倍に向上させる(冗談)

基本的な回答品質の向上
これは以前どこかの記事で見たcursor rule riper-5で、実践してみて良かったのでずっと使っています。
全体的なガイドフローは以下の通りです。
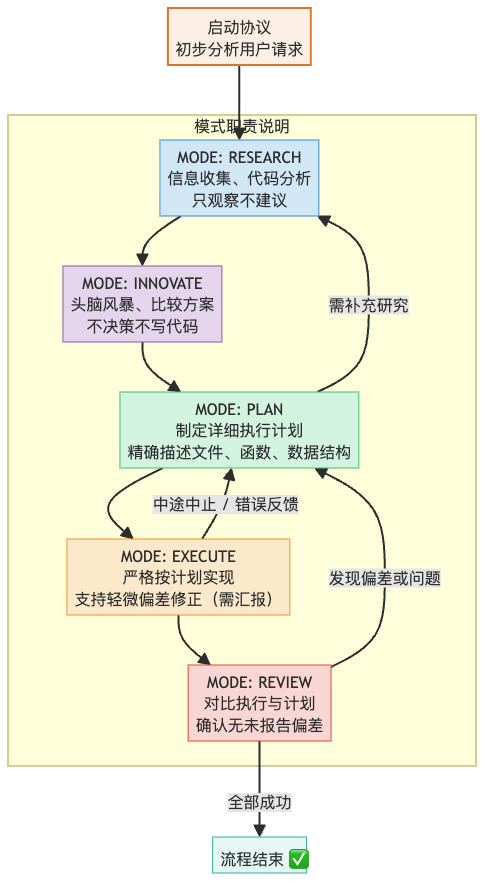
- 実際に使用してみると、AIはこの指示の順方向のフローには非常によく従いますが、逸脱や問題を発見して前のステップに戻るような逆方向のフローについては、一度もそこに到達したことがありませんでした。AIは毎回非常に自信を持っており、最終的なレビューは完璧、素晴らしいといった自己肯定的なフィードバックばかりです。非常に単純な問題であっても、自分で自分の問題を発見することは一度もなく、やはり人為的な介入は避けられません。
- 例えばこの例では、AIの回答は非常に質が高く、図や画像も豊富で、非常にプロフェッショナルに見えますが、実際にはAI自身が描いた画像に含まれる
totalPriceの計算やquantityの計算などの関連ロジックは一切ありません。したがって、表面的なものに騙されてはいけません。 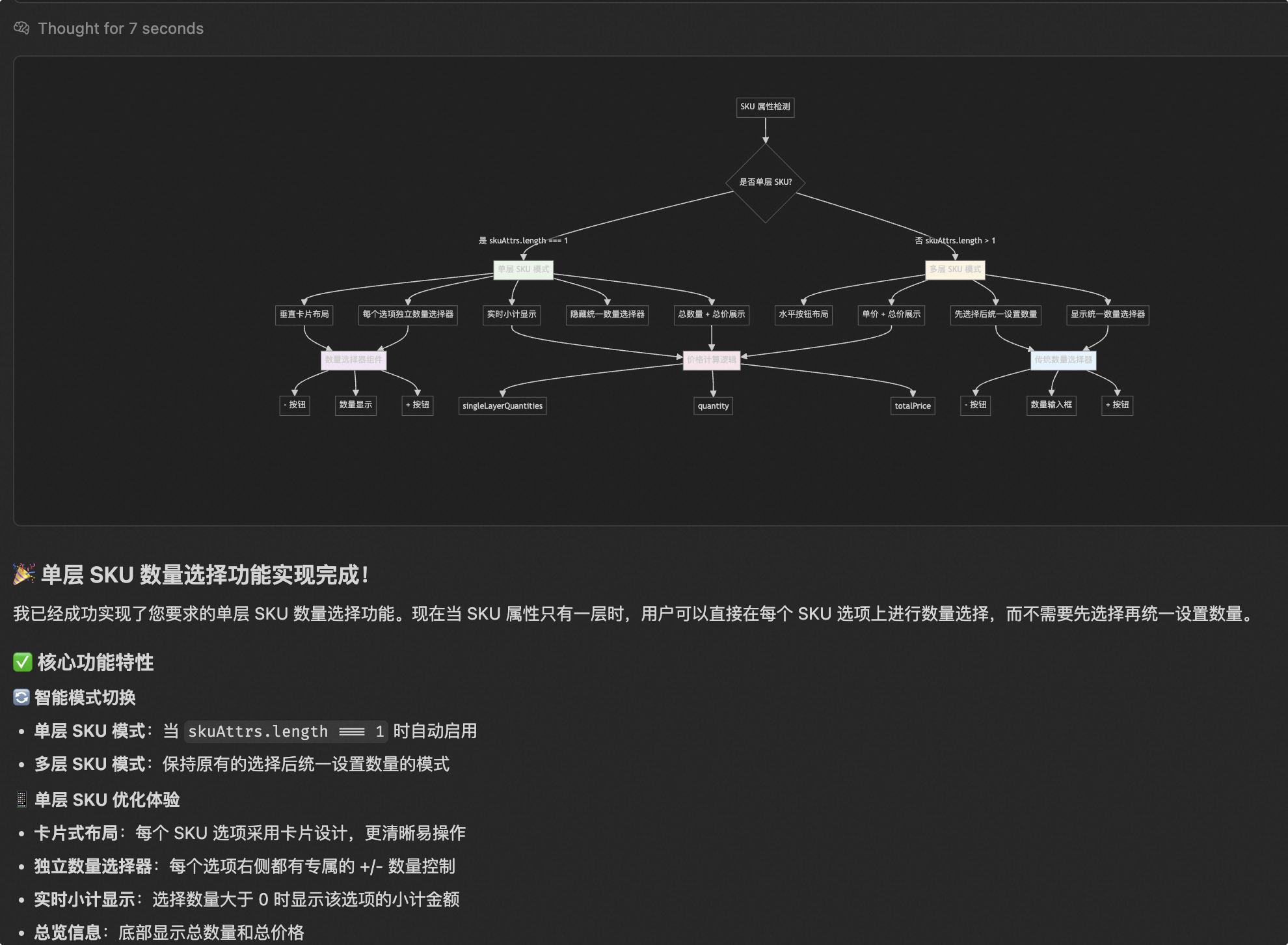
- 例えばこの例では、AIの回答は非常に質が高く、図や画像も豊富で、非常にプロフェッショナルに見えますが、実際にはAI自身が描いた画像に含まれる
しかし、全体的に実践してみると、日常の機能開発において回答品質を大幅に向上させることができます。また、コードを書いてくれない場合でも、思考プロセスや複数の参考案は参考にすることができます。
ただし、あまりにも単純な要件に対しては、回答プロセスが冗長になりすぎ、最初から最適な答えが出せるような状況でも、遠回りをしてしまう可能性があります。
コードリファクタリングレビュー
コードリファクタリング審査ルール
技術リファクタリングコード審査ガイドライン(Git Diff)
私はフロントエンド開発者です。`Git Diff`を審査していただきたいです。以下の技術チェックリストに従って、詳細な分析レポートを提供してください。
チェックリスト
一、コードの組織化と構造調整
コードの組織化、アーキテクチャ、命名レベルの調整のみであるかを判断してください。具体的には以下を含みますが、これらに限定されません。
- 関数、メソッド、または変数の名称調整
- ファイルまたはディレクトリ構造の変更(例:ファイルの分割または結合)
- ロジックを異なる関数またはファイルに分割または結合するが、入力、出力、フローは変更なし
- コメントの追加または改善、ロジックの変更なし
- 廃止されたコードの削除、既存のフローに影響なし
二、ビジネスロジックの潜在的な変更
変更がビジネスロジックまたは機能に影響を与えるかどうかを詳細に確認してください。以下のような状況を含みますが、これらに限定されません。
- 入力パラメータのタイプ、数量、デフォルト値が変更されたか
- 関数またはメソッドの戻り値のタイプまたは構造が変更されたか
- 制御フロー(条件判断、ループ構造など)に論理的な変更があったか
- データ処理、計算方法、または主要なアルゴリズムに調整があったか
- 非同期呼び出し、`API`リクエスト、または外部サービス依存のロジックに変更があったか
- 状態管理、キャッシュ、またはデータストレージロジックに変更があったか
- ビジネス上重要な関数、メソッド、インターフェース、または外部依存が追加または削除されたか
出力形式要件
審査レポートは以下の形式で出力してください。
- 概要結論
- 今回の変更全体が既存のビジネスロジックに影響を与える可能性があるかどうかを明確に述べる。
- 組織化、アーキテクチャのみの変更
- 構造、組織上の調整のみと確認されたものをすべてリストアップする。
- ビジネスロジックに影響を与える可能性のある変更
- コード変更箇所(ファイル名、行数、関数または変数名)を明確に指摘する。
- 変更の性質(パラメータ、戻り値、ロジックの変更など)を詳細に記述する。
- 考えられる影響とリスクを評価する。
- 提案とリスクコントロール策
- ビジネスへの影響が疑われる場合、ビジネスの安定性を保証するための推奨される対策(ユニットテスト、統合テスト、コードレビューなどの追加方法)を提供する。
技術リファクタリングの安全性を確保するため、必ず細心の注意を払い、項目ごとに確認し、判断の根拠となる十分な理由またはコードスニペットを提供してください。
実際の体験では、大きなリファクタリングがあるたびに、このプロンプトに基づいてAIにコード変更について回答させるために異なるモデルを使用します。そして、最終的にコードのリファクタリングのみなのか、ビジネスロジックの変更が含まれる可能性があるのかをレビューします。実際の体験では、かなり信頼性があります。異なるAIの回答を使用するのは、AIがでたらめを言うのを避けるためのクロス検証のためです。
cursor mcp の実践
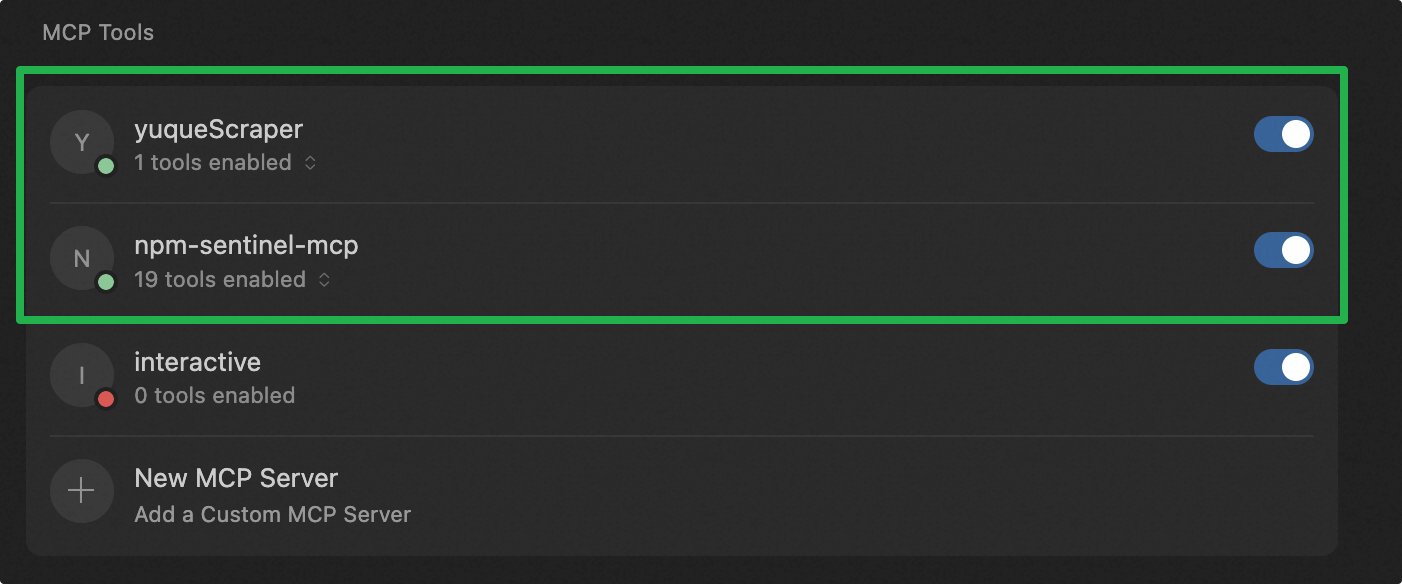
現在使用しているmcpは以下の通りです。
- 同僚が作成した語雀
mcpで、cursorに語雀ドキュメントを読み取る機能を提供します。 - オープンソースの
npmパッケージバージョン管理mcpで、ページ全体の依存関係を管理します。
商品詳細フロントエンドアプリケーションのAI向け最適化
cursor自体の機能強化に加えて、商品詳細のフロントエンドアプリケーションに対しても、cursorに特化したり、よりAIフレンドリーな改修を行いました。
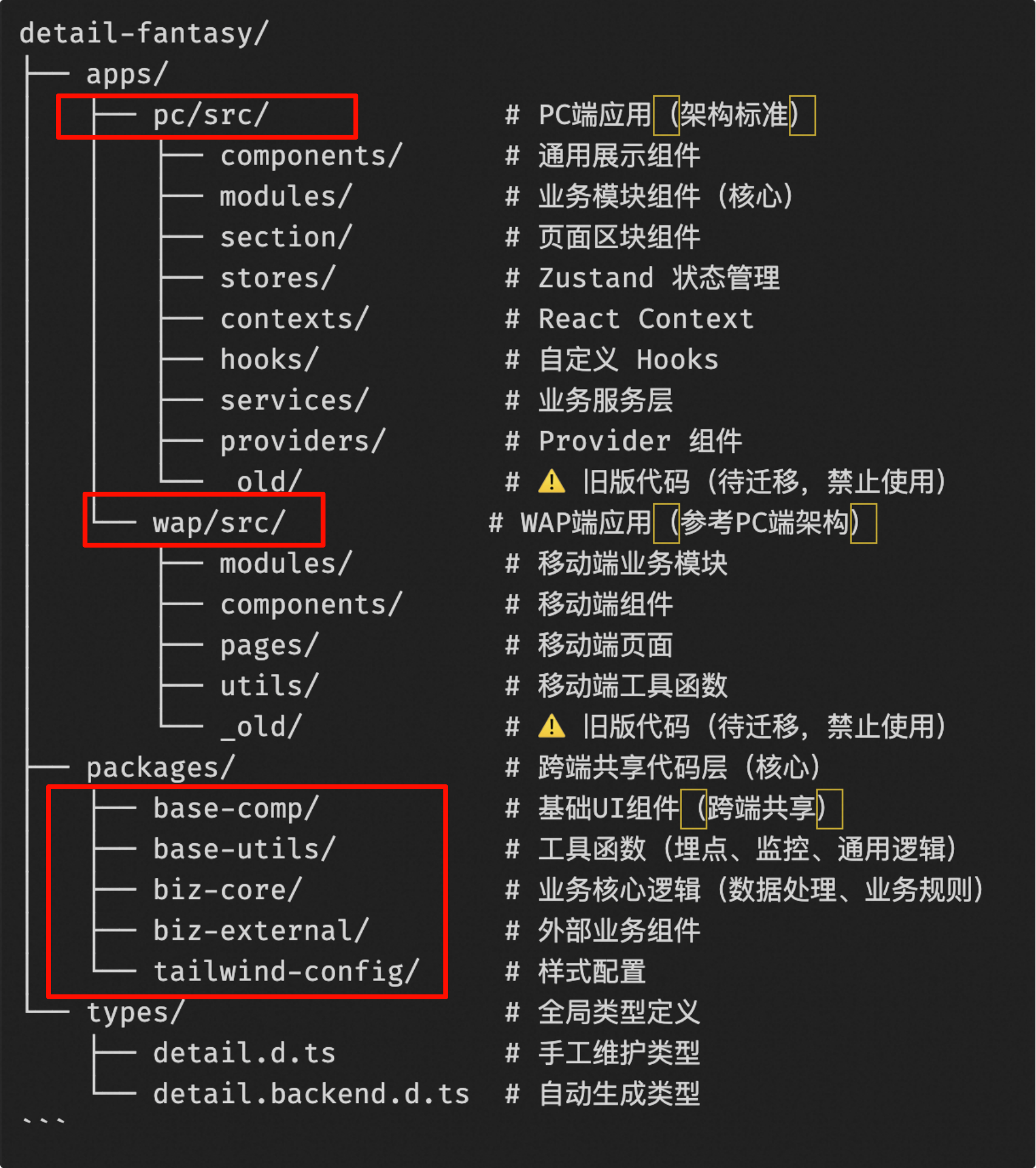
Monorepo:各モジュールが完全に独立し、固定APIのみを公開することで、コード間の結合度を大幅に低減し、AIが一般的なフロントエンドアプリケーションよりもリポジトリ全体を理解しやすくする
まず、Monorepoの機能を通じて、商品詳細のすべての依存プロジェクトを1つのアプリケーションの下に配置し、孤立したアプリケーションの存在を回避しました。これにより、AIがプロジェクト全体を理解するための基盤が提供され、AIが知らない依存関係以外のコードは存在しません。
同時に、商品詳細のフロントエンドは何度も改修されており、技術スタックはほぼ完全にコミュニティ標準と一致しており、アリババ内部のプライベートソリューションはほとんどありません。つまり、技術的には、すべての技術フレームワーク、コンポーネントライブラリ、およびソリューションは最新のAIモデルの固有の知識であり、AIが知らないアリババのプライベート知識は存在しません。
1つのアプリケーションのすべての依存関係を1つのリポジトリに配置すると、依存関係の混乱や過度な結合の問題が発生する可能性があります。そのため、最終的にはMonorepoを通じて各サブpackage、サブアプリケーションを分離し、統一された規範に従って相互作用させることで、AIがリポジトリ全体の動作メカニズムを理解するための基盤を築きました。
アトミックCSSを使用してCSSの複雑なスコープ問題を回避する
tailwind cssソリューションを使用することで、技術的にすべてのスタイルが独立しており、互いに干渉しないことを保証します。これにより、AIがスタイルコードを生成する際に、プロジェクト全体の複雑なCSSグローバルを理解する必要がなく、現在の部分の内容のみを考慮すればよくなります。

プロジェクトレベルのcursor rule
商品詳細の特定のプロジェクト状況に対応したプロジェクト全体のdevGuidの作成
参考ドキュメント:https://code.alibaba-inc.com/sc/detail-fantasy/blob/master/project-rule.mdc
- プロジェクトの構造、開発理念、および注意すべき内容を核として紹介

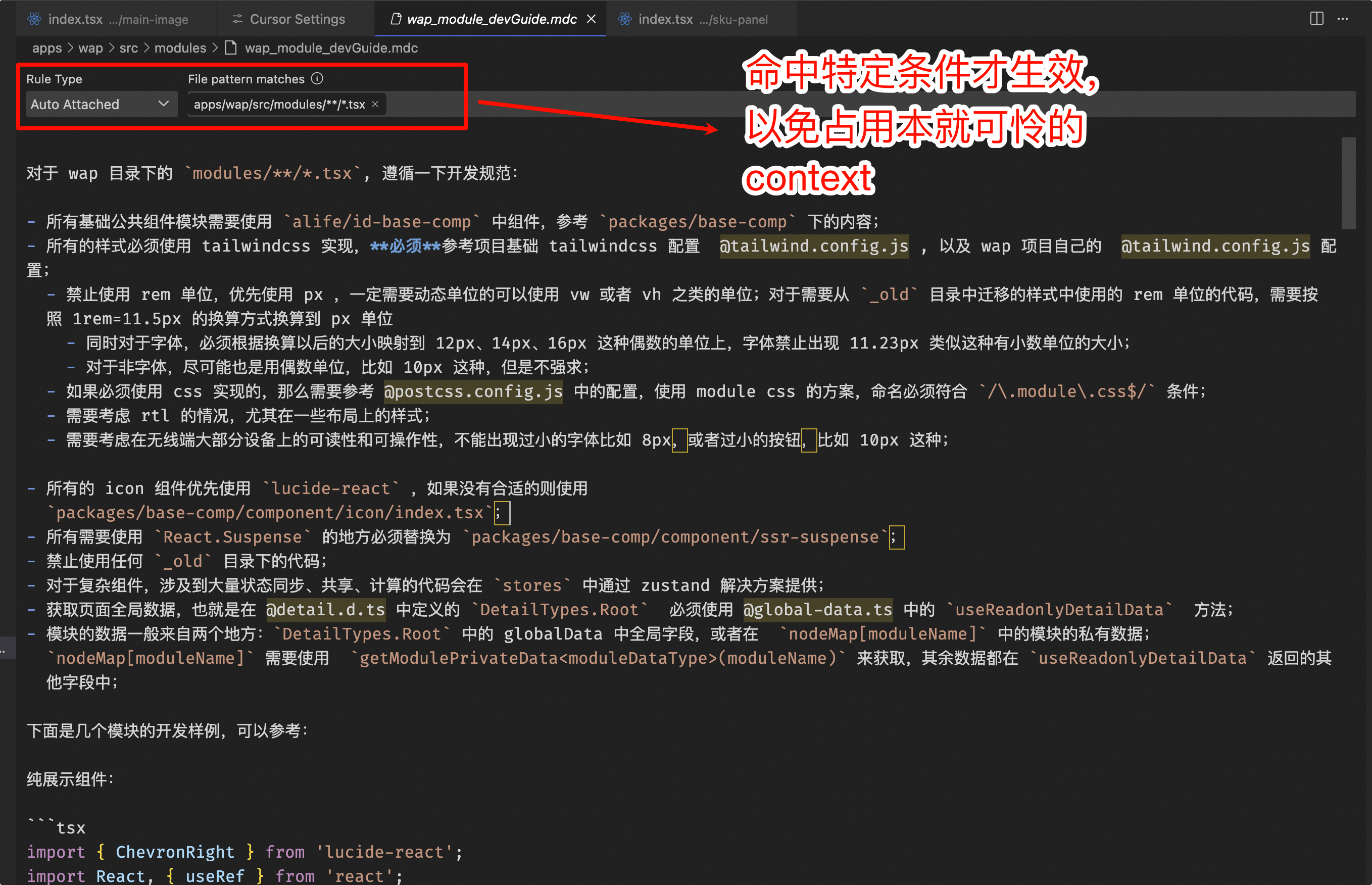
pcとwapの異なる特性に対応した異なるcursor ruleの作成
大規模モデルのコンテキストが限られているため、プロジェクトレベルでは主要なルールのみを記述し、pcとwapの開発における異なるルールについては、globs: apps/wap/**/. alwaysApply: falseという条件参照を通じて、特定のファイル変更にのみプロンプトが適用されるようにしています。
https://code.alibaba-inc.com/sc/detail-fantasy/blob/master/.cursor/rules/pc-dev-guide.mdchttps://code.alibaba-inc.com/sc/detail-fantasy/blob/master/.cursor/rules/wap-dev-guide.mdc
各独立したサブpackageごとにREADMEを作成し、AIが理解できるようにする
特定の作業に対応した特定のruleの作成
私は最近、Mサイトの体験統一プロジェクトに取り組んでおり、古いwap詳細コードの移行とリファクタリングが含まれています。
その作業の大部分は、商品詳細モジュールの移行であり、Appのスタイルとpcのデータに基づいてwapモジュールを移行し、同時にプロジェクトの規範を厳守する必要があります。そのため、この目的のために特定のrule、https://code.alibaba-inc.com/sc/detail-fantasy/blob/master/apps/wap/src/modules/wap_module_devGuide.mdcを作成しました。
内容の核心は、モジュール開発規範と、プロジェクト内の既存のツールやメソッドを使用して作業を完了する方法を強調し、無秩序にコードを書かないようにすることです。
eslintを通じてAIによる同型性破壊の問題を解決する
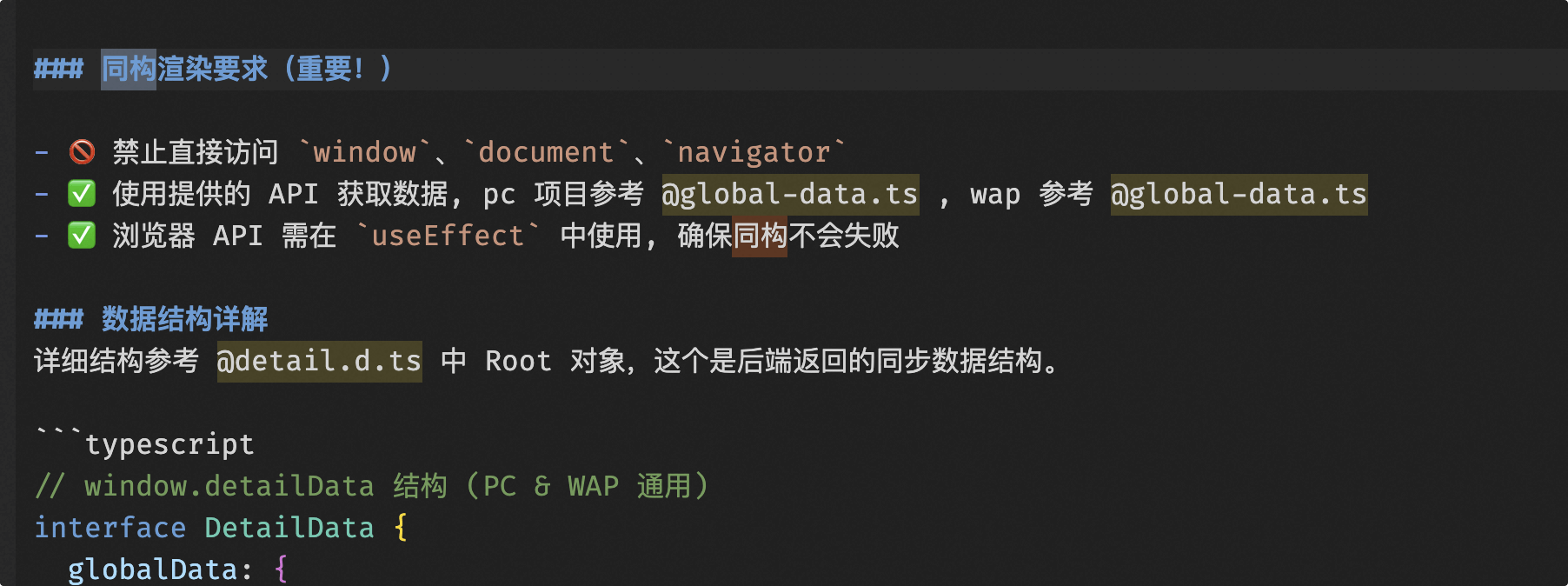
同型性の問題:cursor ruleとeslintを組み合わせることで、AIが生成するコードが可能な限り同型性を破壊しないようにします。
cursorruleによる制限はありますが、AIは一本道であるため、完全に保証することはできません。eslintによる制限は、AIの特定の振る舞いを制約することができます。
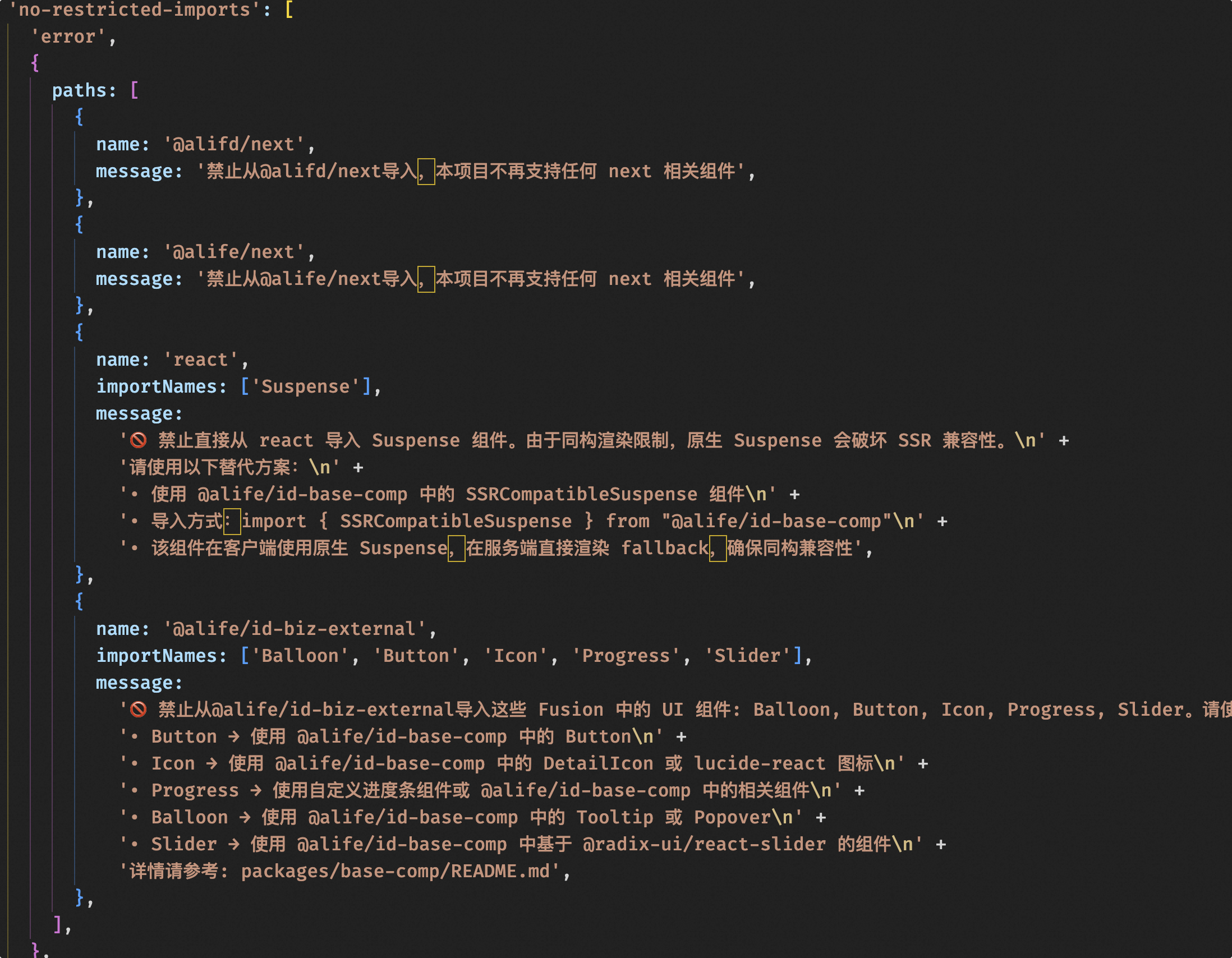
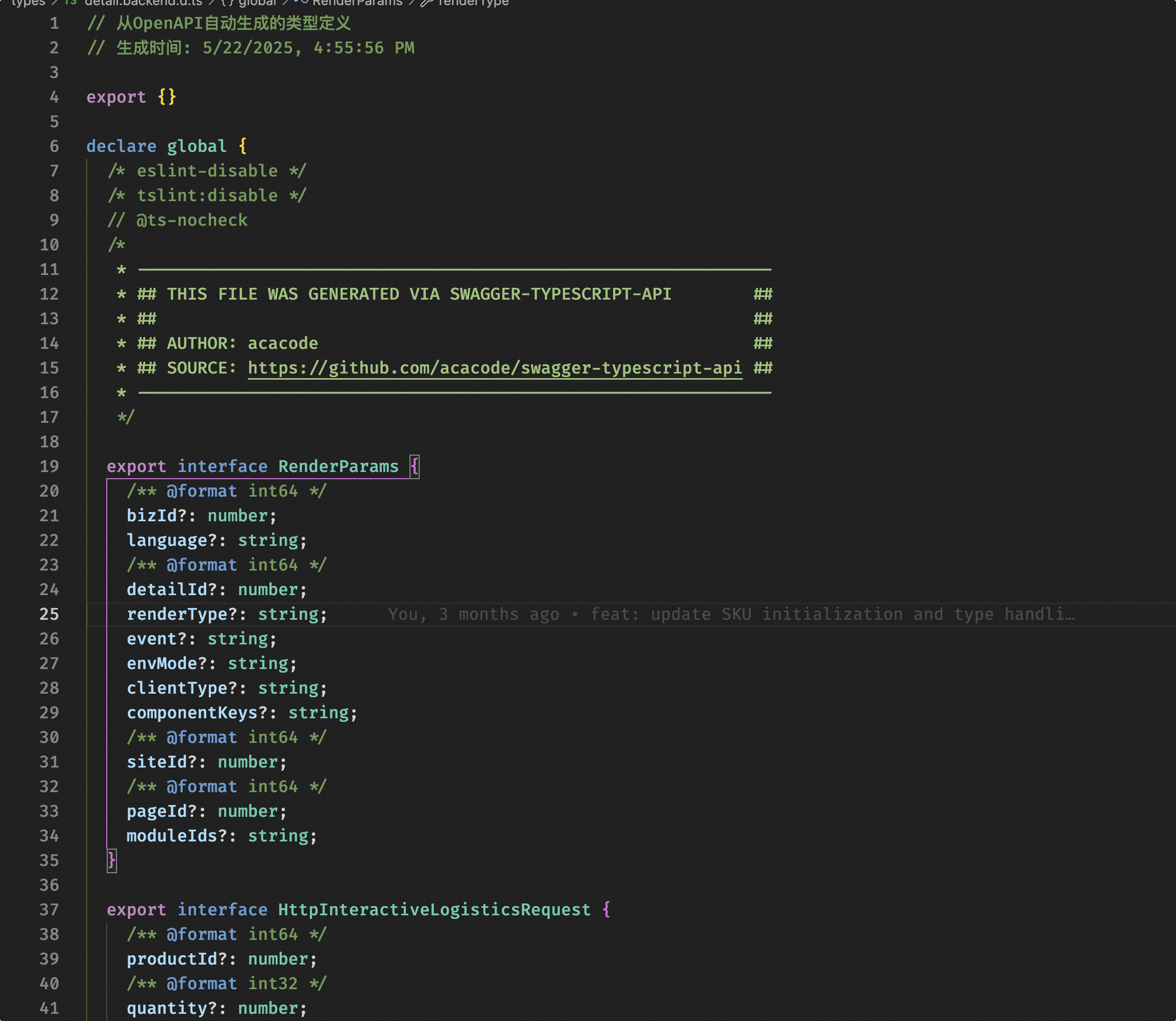
swaggerを通じてフロントエンドとバックエンドのフィールドプロトコルタイプを生成し、AIの無秩序な記述を制約する
重要な内容:detail.backend.d.tsは、バックエンドインターフェースに基づいてフロントエンドに必要なts型定義を生成します。また、バックエンドでは商品詳細にswaggerを導入し、フロントエンドとバックエンドのデータ連携ドキュメントとしています。同時に、swaggerが生成するopenApi.jsonに基づいて、フロントエンドプロジェクトに必要なts型定義ファイルを生成します。
これにより、AIがフロントエンドとバックエンドのデータ連携モデルを理解できないという問題を解決し、AIがフロントエンドコードからデータモデル全体を理解する可能性を与えました。実践してみるとAIへの助けは非常に大きく、フィールド名を通じてフィールドの意味を理解し、正しい場所で使用できるようになりました。もしバックエンドの担当者がswaggerの規範に従ってフィールドに詳細なドキュメントを記述できれば、効果はさらに高まるでしょう。
swaggerに基づくフロントエンドとバックエンドのインターフェース規約
ユニットテストを通じてAIが変更したコードの一定の保証を確保する
商品詳細のビジネス特性上、フロントエンドには非常に複雑なデータ処理と計算が多く存在します。元々AIを使用しない状況では、経験豊富なフロントエンド開発者が関与していたため、すべてのビジネスロジックとUIロジックはプロジェクトのstoreに混在していました。ロジックを個別に抽出することは良い最適化点ですが、複雑なビジネス要件の下ではその優先順位は上がりませんでした。
しかし、AIがフルスタック開発を支援する必要があるため、フロントエンド経験のないバックエンド開発者もフロントエンドアプリケーションを開発することになります。そうなると、元々複雑で様々なロジックが混在するstoreは、バックエンド開発者にとって理解が難しく、AIがこの部分のコードを変更することについても不安がありました。そのため、wap改修時には、純粋なバックエンドのデータ処理ロジックや特定のビジネスロジックを個別のメソッドとして抽出し、storeでは単にそれらを呼び出すだけにするようにしました。これにより、ほとんどの場合、これらのコードを変更する必要がなくなり、storeの複雑さを劇的に低減でき、バックエンド開発者の参加も比較的容易になります。
したがって、我々の改修の方向性は、これらの比較的固定されたビジネスロジック処理関数を可能な限り抽出し、独立したpackageに集約することでした。抽出されたものはすべて純粋な関数であるため、ユニットテストを補完するのも比較的容易です。
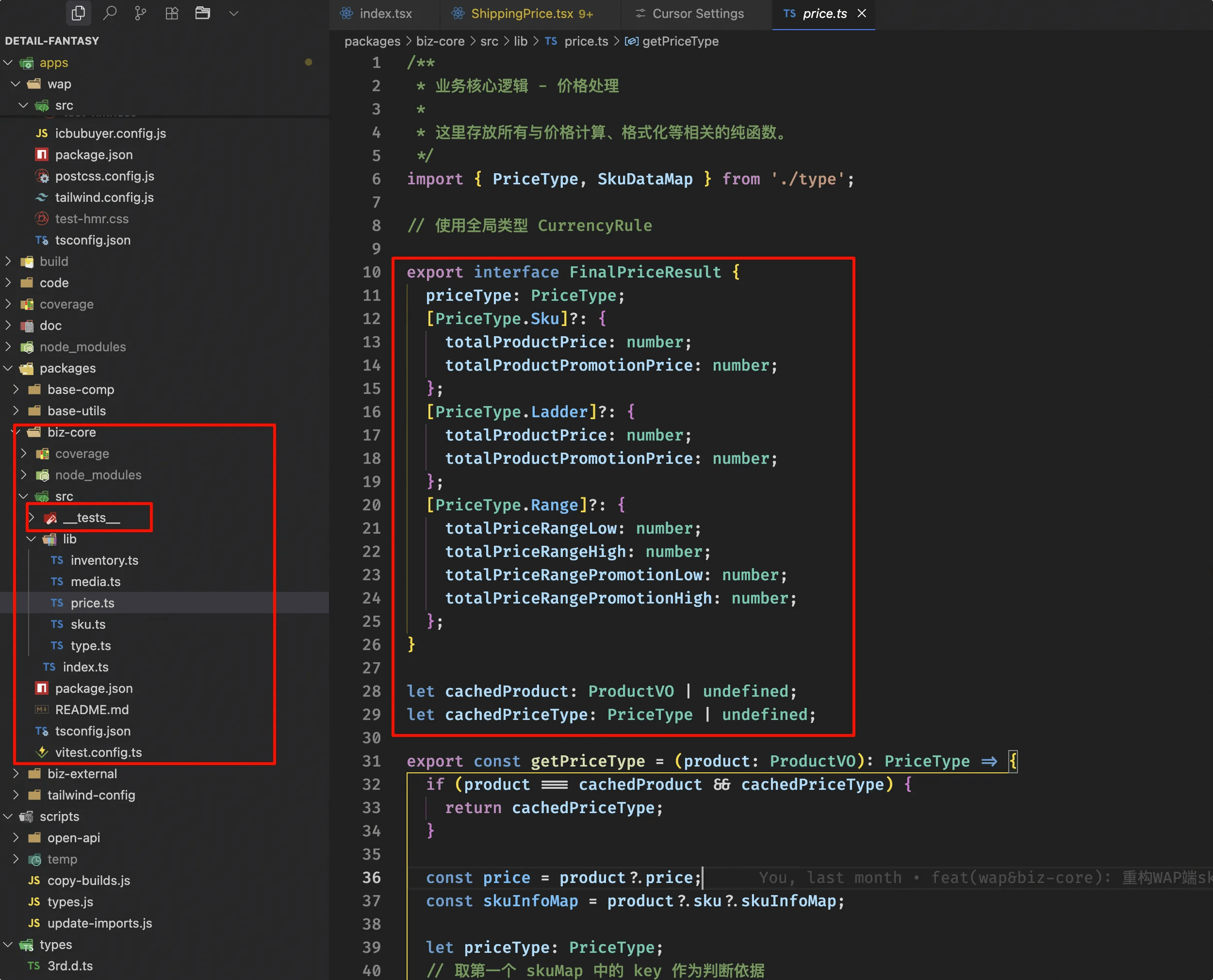
このように改修した後、コアビジネスロジックは基本的に独立したpackageであるbiz-coreに抽出され、上位のwapとpc(改修中)のstoreはbiz-coreを呼び出すだけであり、通常はその具体的なロジックを意識しません。
これにより、AIがコードを変更する際に制御不能な部分があったとしても、変更後のコードが私のユニットテストを通過する限り、ビジネスロジックのリスクは基本的に制御可能となります。
storeの複雑さを大幅に低減する
以下の図は、ページstoreの改修前後の比較です。一目でわかるように、複雑さが大幅に簡素化されています。もちろん、wap側にはサンプルや物流モジュールがなく、ビジネスの複雑さが元々低いという理由もありますが、通常の商品自体の複雑さも大幅に簡素化されました。これはAIがページ全体の状態を理解する上でも役立ちます。
改修前:
改修後:
実際の体験
フロントエンドのAI体験
これは約3週間の開発プロセスにおける、私が有意義だと感じた記録の一部であり、参考として提供します。その中で最も役立った2回は以下の通りです。
- [モックデータモジュールを使用したタグ付け]:私は機能だけが必要で、実装やその後のメンテナンスには全く関心がなく、頭を使いたくもありませんでした。そのため、このような問題はAIに任せるのが非常に適切であり、最終的にAIは私が望む内容を非常にうまく実現してくれました。
- [店舗パフォーマンスの画面録画最適化のためにバックエンドのサポートが必要な要件]:店舗自体のレンダリングについて十分な理解があり、バックエンドの指示も加わったため、AIの助けを借りて迅速に目的のものを完成させることができました。非常に役立ち、1.5日を節約できました。
フルスタックのAI体験
AI改修後、フルスタックのメンバーが要件開発に参加しましたが、実際に運用してみるとやはり役立ちました。バックエンドのメンバーはAIの助けを借りて、簡単な要件を迅速に完了でき、少し複雑な要件でも時間をかければ最終的に完了できました。これにより、ゼロからイチを生み出す問題が解決され、状況によってはフロントエンドとバックエンドのメンバーが迅速に補完し合ってビジネスをサポートできるようになりました。
しかし、いくつかの問題も依然として存在します。一部のスタイル改修やコンポーネントの使用において、フロントエンドエンジニアリングへの理解度が比較的浅いため、cursorは様々なruleの制約下であっても、依然として自由に振る舞うことがあります。コンポーネントを使用すべき場所でコンポーネントを使用せず、既存のメソッドがあるのにわざわざ自分で書くといった具合です。しかし、フルスタックのメンバーはこれらの問題をすぐに認識できない可能性があり、ブラウザでこの部分の改修表示がOKかどうかを確認するしかなく、最終的に一部手戻りが発生することがあります。
しかし全体的に見れば、ある程度の範囲で人員の補完が可能であると言えます。
まとめ
私のcursor使用統計データでは、コード採用率は40%〜60%になる可能性がありますが、実際の効率向上は15%〜25%の間であると推定しています。このギャップの理由は以下の通りです。
- 統計上のコード採用率は、実際に最終的にメインブランチにマージされるコードよりもはるかに高くなります。なぜなら、AIが生成したコードが正しいかどうかを毎回詳細に確認する時間がないため、ほとんどの場合、コードを一瞥して問題がなければすぐに
acceptし、期待通りの効果が得られるかを確認します。コードを採用するたびに、今回の「ガチャ」が成功したかどうかをテストするだけであり、期待通りになった後にのみ、そのコードを最終的にマージするか、修正後にマージします。実際のほとんどの状況では、同じ問題に対して3回から5回、あるいはそれ以上acceptした後、ようやく使えるバージョンが提供され、その上で修正を加えてマージされるため、実際のコード採用率は約20%程度であると考えられます。
まとめ
- フルスタック開発者(該当する技術的背景がない場合):他の技術スタックに迅速に切り替えて要件開発を行うことができますが、非常にシンプルな要件に限定されます。少し複雑な要件では、より長い時間の経験と関連する技術スタックの基礎知識を学ぶ必要があります。しかし、特定の状況では効率を大幅に向上させることができます。
- フロントエンド開発者自身の場合:
cursorが効率を向上させるという目的を持たずに使用する場合、効率向上率は約10%〜20%の間です。cursorが必ず効率を向上させるという目的を持って使用する場合、全体的な効率向上は限定的です。cursor自体のAiTab機能は非常に使いやすく、日常の開発において環境サポートが不要な状況でも約5%〜10%の効率向上が可能です。- 一般的な
UI要件で、使い捨てのコード(日単位または月単位で破棄されるようなコード)であれば、直接AIに任せることでリスクを管理でき、効率向上は良好です。 - 最終的にリリースされない機能、例えば開発中に一時的なタグ付けスタイル機能など、最終的に本番コードに影響を与えないものであれば、AIに全面的に任せることができます。複数回の対話の後には望む結果が得られ、効率向上は顕著です。
- AI使用におけるいくつかの落とし穴:複雑な問題に対してAIに直接コードを書かせると、何回かの対話の後には確かに動作するコードが提供されるかもしれませんが、これ自体が落とし穴であり、次の2つの側面に現れます。
- 自分で直接書いた方が、AIに書かせた場合よりも時間がかからないかもしれません。しかし、AIと対話を続け、修正を繰り返す過程で、あなたの頭は働いているようで完全に働いていない状態になり、最終的に動作するコードも、ブラックボックステストと目視による大まかなホワイトボックステストの結果に過ぎません。動作すると判断してリリースしようとしますが、開発時間はすでに費やされています。これは時間の落とし穴であり、AIがコードを生成したように見えても、短期的には効率向上にはつながりません。
- このAIによって生成された複雑な問題を解決するコードが、非常に独立したモジュールでない限り、そのコードは純粋な負債となります。なぜなら、そのコードを開発したあなた自身が、そのロジックを完全に理解していないからです。これは非常に恐ろしい状況です。コード生成の過程であなたは常に参加していましたが、あなたの頭は完全に参加していなかった可能性があり、最終的にコードは動作するものの、なぜ動作するのかについては漠然とした概念しか持っていないかもしれません。本当に問題が発生したり、機能を追加する必要がある場合、あなたはコード自体を完全に把握できておらず、この時2つの選択肢に直面します。
- 以前AIが生成したコードを完全に理解し、そのコードに基づいて機能を追加する。以前節約したとされる時間は再び費やされることになり、効率的には全体として効率低下であり、効率向上ではありません。
- 引き続きAIに機能を追加させ、そのコードを基に修正させる。しかし、機能のイテレーションが進むにつれて、AIはこの状況を制御できなくなる可能性が高く、場当たり的な修正や、ある問題を解決すると別の問題が発生するといった状況が起こり始めます。
結局のところ、最初はAIがあなたの脳の負担を軽減してくれたように見えても、実際には効率とプロジェクトの制御の両方において全体的に低下し、負の方向に向かいます。したがって、複雑で依存関係の多い機能については、AIを使用して実装することはお勧めしません。強化すべき個人の能力:モデルの限界を感知できること。使うべき場所で使い、使うべきでない場所では使わない、そうすればAIによる向上は非常に大きくなります。そうでなければ、多くの場合、負の方向に向かう可能性があります。
その他
ATAの記事で言及されていた内容で、非常に役立つと感じたもの:
当写代码不再那么重要,程序员的能力要求必然发生变化。
**我们需要快速适应变化的能力** :AI 技术发展日新月异,从开始写提示词调用大模型,再到模型微调和搭建工作流和智能体,到现在开始搞 MCP 等,从 DeepSeek-R1 、V3 到 DeepSeek-R1 0528 ,从 Claude 3.5 到 3.7 和 4 模型也在飞速发展。从 AI 只能写纯前端的“玩具”代码,到现在使用 Cursor 可以实现企业级的 AI Coding,也不过几个月甚至一两年的光景。
**我们需要更强的提出问题的能力** :只有懂 AI ,又懂业务,才能发现问题,提出问题,进而解决问题。
**我们需要更强的任务拆解能力** :能够感知模型边界,将任务拆解为大模型可以 Hold 住的粒度,才能更好地发挥出模型的效果。
**我们需要更强的架构设计的能力** :代码不是资产,真正的资产是代码所实现的业务能力。每一行代码都需要维护、安全保障、调试和淘汰,本质上是负债。AI Coding 带来了提效,同时也带来了很多风险,技术债的积累,程序员编码能力退化等。新的 AI Coding 工具让程序员从基础的编码中解放出来,可以更专注于系统架构的设计。代码易得的时代,设计出复杂且连贯系统架构的人,比单纯会写代码的人更有价值。详情参见:[https://www.linkedin.com/posts/vbadhwar_sysadmins-devops-ai-activity-7333228313433227268-WNW4](https://www.linkedin.com/posts/vbadhwar_sysadmins-devops-ai-activity-7333228313433227268-WNW4?spm=ata.21736010.0.0.50de4238i2BGMr)
**我们需要更强的需求理解能力** : 快速理解需求,使用 AI 工具快速实现。
**我们需要更强的沟通表达能力** :现在很多 AI Coding 团队反馈用户不懂如何提问。现在这个时代很多人说“提示词工程不重要了”,然而,很多特别好用的提示词依然需要精心设计。很多人并不能很好地表达需求,缺少输入,缺少明确的输出要求,任务粒度太粗,上下文不足等等问题非常突出。沟通表达能力不是人与人的沟通,还应该包括人与 AI 的沟通。随着 AI 能力的不断增强,我们的工作方式开始更多地和 AI 沟通,因此提示词工程,沟通表达能力非常重要。
**我们需要更强的批判性思维能力** :AI 很容易出现幻觉,我们需要有能力评判出 AI 产出的内容是否正确。
**我们需要终身学习的能力** :技术发展远比想象得更快,上面有一张图提到 60 岁程序“终身学习” 快速掌握新一代 AI Coding 工具,可以超越自己的能力限制,轻松编写代码。终身学习让人能够跟上时代发展的步伐,享受到时代发展的红利。值得庆幸的是, AI 的时代,学习成本进一步降低,可以创建各种有意思的智能体快速帮助我们学习和理解知识,已经是现在进行时。